Composing callables is a typical and useful functionality one could ask from a programming language. The canonical explanation of composition includes the example:
h(x) = f(g(x)) = (f * g)(x)
i.e. h is the composition of two functions, namely f and g. This means the effect of calling h is that of calling f with the result of g(x).
Being statically typed, C++ may appear as a nightmare of a language to express such mutations. After all what would be the type of an entity that produces a composition out of arbitrary callables? Luckily, such a view couldn’t be further from the truth; not only is such a utility expressable in core C++ (no third party libraries needed), but also consistitutes a prime example where many modern C++ features simplify the code and facilitate the end result.
Usage of such a construct would allow to chain an arbitrary amount of callables where the result of each one can be passed to the next:
auto h = compose(g, f, z);
h(x);
As shown in the following Demo, the first callable can even have an arbitrary amount of arguments, but subsequent ones must accept the result of the previous call as a parameter. Let’s now list the modern C++ features that allow us to write this code, along with the language version that introduced them:
Line 6 (C++20): Variadic capture clause, allows us to capture an arbitrary amount of callables into the lambda.
Line 7 (C++20): Template syntax for generic lambda expression. This comes in handy when forwarding the xs parameters to the callable, because their type is now readily available and I don’t have to resort to more bloated syntax like “decltype(xs)...“. It also facilitates writing requirements (see next point).
Line 8 (C++20): Constraint to prevent composition chains where the callable cannot be invoked with the provided argument(s), also allowing better compilation error messages.
Line 10 (C++17): constexpr if allows compile time branching to treat our two cases, namely that of Fs being greater than zero vs zero.
Lines 13 & 18 (C++17): std::invoke is a standard library function which enables us to invoke arbitrary callables with a unified syntax.
The only “tricky” line in the code above, is the return statement in Line 12, which says: call compose again, only now
the list of functions is the “tail” of the current function list, and
the argument to that “new” composition is the result of calling the “head” with xs i.e. fun(xs...).
A library solution
Addressing composition in modern C++ wouldn’t be complete unless we mention standard library facilities can help, e.g.:
using std::views::transform;
auto fgh = transform(h) | transform(g) | transform(f);
// Calculate f( g( h(x) ) )
auto fgh_x = ranges::single_view{42} | fgh;
fgh_x[0]; // Result is the only element in the view.
If pulling from a single element view is not something you find awkward, or even bettern you’d like to apply the composition to a collection of inputs, you can even create an abstraction similar to what we described above using fold expressions (Demo):
template <class... Fs>
auto composer(Fs&&... functions)
{
using std::views::transform;
return (transform(functions) | ...);
}
Sanitizers are tools embedded in gcc or clang, that can instrument your code to check for various error categories like:
Memory and address violations.
Threading problems.
Undefined behavior.
This post shows how to incorporate such tools to your continuous integration pipeline for C++ code and provides an open source repository of reusable sanitizer workflows for GitHub.
What is a sanitizer good for?
There’s countless ways to mess up a C++ program, but many problems boil down to memory or threading issues. Let’s look at two silly programs that fall into these categories:
// 1.
{
auto d{ new double };
}
// 2.
{
int val = 0;
auto task = std::async([&val] {
int i(0);
while (i++ < 1'000)
{
++val;
}
});
if (val == 1'000) {
cout << "Updates finished";
}
task.get();
}
In the first case, the address sanitizer will report the memory leak, adding the source location that generated it:
=============================================
==2153==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 8 byte(s) in 1 object(s) allocated from:
#0 0x7fe48d1d6587 in operator new(unsigned long)
../../../../src/libsanitizer/asan/asan_new_delete.cc:104
test_asan.cpp:5
The second error case can be handled by the thread sanitizer. It recognizes the potential for a data race when reading val, while being modified by task.
==================
WARNING: ThreadSanitizer: data race (pid=2209) 2: Write of size 4 at 0x7ffe61a62a3c by thread T1:
Drilling down to the culprit of threading issues might be more convoluted, although the exact location of unsafe access is again given. An awesome bonus is that thread sanitizer has (almost) zero false positives, which makes it much more useful compared to similar tools.
Testing frameworks running with sanitizers
A sanitizer can be enabled by providing the '-fsanitize=' option to your compiler. Of course for complicated projects with intricate dependencies, configuring your build system will be a bigger challenge. When the sanitizer of choice is enabled, this will make your test suite run against the instrumented code.
Note that if you’re using third-party libraries you’ll have to also compile those with sanitizer support or else a sanitizer cannot peer through them. Even so, problems in third party libraries will be reported with restricted information about the internals that caused them. This is an excellent starting point and a very big help when evaluating the integration of third party components to your code-base.
When running a test suite over sanitizer-instrumented code, say GoogleTest, run time execution will spit out problems reported by the sanitizer as well. For example:
2: Note: Google Test filter = TestMyTest.TestCase
2: [==========] Running 1 test from 1 test suite.
2: [----------] Global test environment set-up.
2: [----------] 1 test from TestThreadSanitizer
2: [ RUN ] TestThreadSanitizer.DataRace
2: ================
2: WARNING: ThreadSanitizer: data race (pid=2209)
2: Write of size 4 at 0x7ffe61a62a3c by thread T1:
2: #0 operator() /home/runner/work/sanitizer_workflows/sanitizer_workflows
...
These magical “WARNING” and “ERROR” keywords will trigger your testing framework; the test will fail. Simply by running your test suite through your sanitizer of choice, the tests not only check the observable behavior, but also verify that all runs correctly under the hood and no latent bugs are left in the code.
Reusable GitHub workflows
I have created a repository with reusable workflows for my two favorite sanitizer configurations: thread and address sanitizer. Using the workflows is described therein, but in summary it just takes defining a yaml file like:
name: Memory
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
address_sanitizer:
uses: picanumber/sanitizer_workflows/.github/workflows/asan.yml@main
with:
testDir: 'tests' # Optional, default value is 'tests'
Example
The yapp library, heavily depends on threading integrity. It follows the guide in sanitizer_workflows to provide the sanitizer checks:
We can think of a pipeline as the computing analog of an assembly line. A pipeline is a data processing mechanism composed of a sequence of stages. Data progresses from one stage to the next, occupying one stage at a time. This lifts concerns on data races, and allows stages to use their own computational context (dedicated thread, device, system). Finally, buffering can be used between stages to regulate varying latency of computations.
The parallel pipeline pattern can be identified in:
The Unix instruction pipeline
The OpenGL programming model
CI / CD pipelines
Anything that has to do with real-time or streaming data processing
A more specialized adaptation of the pattern can be found in “instruction pipelining” within a processor. As shown below, there can be four stages to this pipeline (fetch, decode, execute, write-back), while the completion of an instruction can be viewed as the output. The control unit plays the role of the generator, arranging for a flow to start, continue and stop as a program commands.
In its general software implementation, a pipeline is composed of three types of stages:
A generator stage. This is the stage that pumps data into the pipeline and can be placed at the front of a pipeline. A pipeline should be operational with unbound generators, i.e. an “infinite” data stream.
Intermediate stages, processing stages or transformation stages. These are the stages that take some input and produce some output. A pipeline can have an arbitrary amount of such stages.
Sink or output stage. This stage extracts data from the pipeline and can be placed at the back of a pipeline.
Of course no-one prevents intermediate stages to also output “intermediate” results, but in general pipelines are expected to produce on a single end. Secondary reasons like debugging may force us to inspect data half way through, but that is a “side-concern”.
yet another parallel pipeline
A multi-threaded implementation of the pipeline pattern can be found in yapp. It is an alternative to pipelines in large general purpose multi-threading libraries, aspiring to:
Smoothly collaborate with code using standard thread facilities.
Avoid the (bigger) learning curve.
Provide “just use the pipeline part”.
yap sports:
Zero dependencies.
Header-only implementation.
Vanilla c++20.
Exclusive use of C++ standard facilities like <thread> and friends.
Meta-programmed stitching of user-provided callable objects into pipelines.
k most frequent words
In searching for a “hands-on” example using pipelines, we should consider that many text processing tasks can be solved in a pipeline:
Find all occurrences of a word.
Find all misspelled words.
Translate a text – OK, technology has advanced here so we might be looking at a different universe with this one.
Find the number of individual words, or extract other metrics on “language quality”.
An interesting variation is the following: Given a text file and a positive integer number K, return the K most frequent words in that text. This process can be modeled as pipeline with the following steps:
Read the input file line by line.
Break each line into a list of words.
Place each word into a hash table, mapping the word to its frequency.
Use newly discovered <word,frequency> pairs to maintain a K-top list of words.
This is written in yap as:
auto pl = yap::Pipeline{}
| Reader(name) | Splitter{} | Frequency{} | KTop(k);
pl.consume(); // Use all data from the generator.
While step (1) is generating lines (reading the input), subsequent steps are already processing data in their own thread. By the time input reading is finished, we are pretty much done processing. Full code is provided here, but to drive the point home it’s worth looking at the file reader implementation:
class Reader
{
std::ifstream _input;
public:
Reader(const char *fname) : _input(fname)
{
if (!_input.is_open())
throw std::logic_error("Cannot open input file");
}
std::string operator()()
{
std::string line;
if (!std::getline(_input, line))
{
throw yap::GeneratorExit{};
}
return line;
}
};
Every time the reader is invoked, it pushes a single line from the input file to the pipeline. Subsequent steps start working with that line as described in steps 2-4. Pipelines are usually “ever-running” (or until their .stop()method is called) but in this case we need to process a predefined amount of data, namely all of the input file. To signal the “end of input”, the generator throws the GeneratorExit exception (if you know what I’m saying), while the call to consume is to block until all data has been processed.
You can read on all the available operations here.
Outro
This example concludes our introduction to pipelines and the yap library. Hopefully it was enough to motivate you to apply the pattern in your code and search for potential optimizations or improvement in organization that it may introduce.
Can you enforce user code to provide correct specializations? This article provides one way of doing it.
1. Specializations
Class template specializations are used to provide a custom behavior for your type of choice. Think for example the property of something being serializable, one might express it as:
template <class>
struct Serializable
{
// By default a type is considered "non-serializable"
constexpr static bool value = false;
};
We call the above a “base template”, meaning it’s the non-specialized version that applies to every type argument, while a specialization is expected whenever someone wants to customize this behavior. To make things more concrete, a library using this trait might write:
To land on “branch 1”, you have to specialize the base template. But how do you do that? Usually the author may leave a hint on the base template like so:
Such a hint does not have to be in comments because the silent contract is that library code will never try to use the two de/serialization functions when value is false. Following such a hint, users are expected to provide the following customization for their type:
You might have already deduced that this “user provided specialization” is the part we’re trying to make safer or fail-proof. How can one ensure that a user provided specialization “follows the rules”? To be more specific, in our example providing such a customization comes with the following challenges:
Just forgetting constexpr or static in the declaration of value will lead in all sorts of interesting compilation or link time errors. The definition of value in a specialization is only enforced by reverse engineering the errors that result from its absence. What if we want to change the base template value to be int, what if mixing int and bool mostly works any-ways?
toString and fromString face similar problems. The author of Serializable expects them to have very specific signatures but has no means of enforcing them, like inheritance does with the combination of virtual and override. Again some variation may pass compilation, like passing by value in fromString, but this can spuriously kill performance or go against the grain in terms of design/intentions of the author of serializable.
3. A legacy solution
Legacy systems, typically addressed this by providing alternatives to “hand-written” specializations. For example boost geometry has a vast type specification system that builds on top of this logic (oversimplifying here, bg is amazing and did concept-like stuff before c++11). Instead of writing your specializations, you use macros to generate them for you, e.g.:
BOOST_GEOMETRY_REGISTER_POINT_3D(...
Since I’m not above using a macro, I’ll provide arguments on why I want to avoid them. To its core, the macro is a code generation facility; while powerful and alluring to experts, it doesn’t prioritize our needs in this case:
It doesn’t provide type restriction (quite the contrary) and
The kind of errors I’m trying to avoid can easily be generated by cunning experts or puzzled novices. Just pass names decorated with const& and friends to the macro declaration.
Furthermore, when we do break the macro, our compilation error has one or more extra level of indirection – not fun.
4. A concept based solution
On the contrary, using concepts here can totally cover our needs:
Type checking – check
Member existence – check
Do all that in compile time – check
Non intrusive to the user type – check
The last point is of great importance to library developers, since removing the need to modify “user code” is a big plus: user code does not have to inherit, does not have to provide a specific layout, heck it can even be written in C. All the library mandates is that you write the specialization correctly.
5. Implementation
Start by declaring your restrictions. In our example that would be:
Every specialization of Serializable must contain a value member of the appropriate type.
Every specialization of Serializable must contain a serialization/deserialization function of appropriate type.
Combine the above requirements in a Serializability concept. A type can either
provide a specialization, hence true == Serializable<T>::value + restriction (2) must be true.
follow the base template, hence false == Serializable<T>::value, in which case there is no extra requirement.
Next we need one final piece of machinery. That is to expose a “library facing” trait like so:
template <Serializability T>
constexpr bool serialize_v = Serializable<T>::value;
// Using the above utility, a library writer can write:
if constexpr (serialize_v<T>) { // ...
Attention!one might be tempted to use the concept as trait, like if constexpr (Serializability<T>) and be done with it, but that’s not what we want. The aforementioned concept is permitted to be true or false. In case user code incorrectly specializes our base template we end up with legal code and a concept that evaluates to false. But that’s not what we want; our goal was to “ban incorrect specializations“. The serialize_v trait, enforces Serializability to hold (i.e. either you’re unspecialized or correctly specialized), and uses the nested value as the target for compile time branching.
An example implementation can be found here, with a proper specilization of a user type branching on whether it’s serializable or not.
To extend the example, one can imagine user code that incorrectly specializes, by forgetting the const in the toString method:
This post deals with the design and implementation of a locking wrapper. It is organized into the following four sections:
Description – the functionality of such a wrapper is described.
Motivation – scenarios that exemplify such a utility are presented.
Implementation – one such implementation is provided in C++
Special cases and considerations regarding ownership
So without further ado, let’s dive in.
Description of a locking wrapper
Simply put, a locking wrapper is a class that is able to encapsulate another class to make its functionality thread-safe by means of creating critical sections around its interface. So for example, if you class provides a method foo, the wrapper’s duty is to provide an instrumented access to that method with the following semantics:
lock some internal mutex
call foo
unlock the internal mutex
This “decorated” call sequence adds thread safety to a class that was designed without such provision.
Motivation for such a class
Do use such a wrapper if:
Lock-unlock sequences is the desired granularity of synchronization primitives you want to use.
You want to separate a class implementation from provision for thread safety.
The multi-threaded use case is a fraction of the class’ use cases, and you don’t want to redesign the whole class for that fraction.
You want to prototype using a completely synchronized version of the class, and plan to refine later.
You have a scenario where each data member is paired with a mutex, and you simply want to abstract all the boilerplate noise away.
Don’t use such a wrapper if:
The class is heavily used in multi-threaded code (e.g. it’s a building block for other multi-threading code) and locking its methods using the same mutex is a performance killer.
Using thread-local instances would suffice. Of course it may be the case that both wrapped instances exist and thread-local ones, in which case it’s beneficial to separate the class from its thread-safety mechanisms.
Implementation
The code that follows is implemented as a special case of the generic wrapper, presented in a Bjarne Stroustrup paper. Therein, the creator of C++ shows a way of generically decorating a class in order to apply some prefix and postfix calls around a method. In our case, the prefix call is the one to lock the mutex, while the postfix is tasked with unlocking it.
With that in mind, a general skeleton for our wrapper is easy to devise:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Using this mechanism you can call any method from the class using the arrow operator, and it will be protected by a single mutex:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As you can see our Locking class holds a mutex to synchronize access to the wrapped object’s methods. Implementing the prefix decoration is as easy as locking the internal mutex before returning a pointer to the object. It’s the postfix implementation were things get interesting:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The postfix call is implemented with the help of a call proxy. As seen above this is an object that is created on the spot by the arrow operation, and implements the postfix call in its destructor. Using this design in our case, by the time the expression “->f(msg)” is complete, you have three things happening:
The internal mutex is locked.
A call proxy is returned, which can give you access to the wrapped object, hence you can call any of its methods.
The call proxy is destroyed, at which point the mutex is unlocked.
The complete functionality is shown below, with the call proxy implemented as a nested class for our wrapper:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For those that went through the paper, you may have noticed that we chose to avoid using pointers to refer to the wrapped data; instead forwarding references are leveraged to construct the data in place, and avoid weird lifetime scenarios or the resource being shared with non thread-safe use. Of course one can always circumvent this by using reference types or smart pointers, but I’m not in the business of providing bullet-proof boots.
Using smart pointers can be a valid case, when they’re handed exclusively to the thread-safe wrapper (or if you can somehow guarantee that they’re not being used while we try to use them through the wrapper). Below we summarize some examples of using smart pointers with our locking wrapper, which were also shown in the linked demo:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
One of my favorite blogs, is Raymond Chen’s “The Old New Thing”. In a recent post, he described a way to find a type in a tuple, with a compile time predicate that given a type and a tuple, will return the index of that type in the tuple, or fail to compile if the type does not exist (or exists more than once):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The value is calculated at compile time and all is good in the world, no?
You can follow the link to check his implementation, Raymond offers a great walk-through as always. The thing that bothers me is the use of recursive template instantiations. This happens when a template instantiates itself until it hits a termination case. The reason I dislike the technique is because it tends to:
Increase the binary size. Symbols are generated for a chain of instantiations which end up bloating the executable.
Slow down compilation. It’s a recursion and the compiler has to pay the price up front.
Complicate the error messages when something goes wrong. The compiler will spit out the whole recursion tree when something goes wrong, and the error messages get obfuscated.
There’s a chapter called “The Cost of Recursive Instantiation” in the template book, but what I’ve found really dangerous is that when trying to scale code designed this way the burden on the compiler may get out of hand. E.g. we may start adding nested types in such templates or try to piggy back on the recursion to design extra machinery.
Of course in the problem at hand, Raymond’s implementation is simple and efficient (even checked binary outputs and resulting generated symbol – as always you can trust what he’s saying). I’m writing this post to show there’s usually an alternative and to point out that not considering the cost of these things may haunt you in the future.
Let’s see how a non recursive implementation would look like:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This fold is binary to handle empty parameter packs. The “match_v” predicate (1) checks if a type “T” exist at index “I” in a tuple “Tuple”. We can see what an example instantiation would do:
type_index<int, tuple<char, bool, int>>
// T = int
// Tuple = tuple<char, bool, int>
// Args... = char, bool, int
// Is = 0, 1, 2 -> index sequence of cardinality = sizeof...(Args)
// If we denote as "m" the "match_v" predicate, we have
(0 * m<int,0,Tuple> + (1 * m<int,1,Tuple> + (2 * m<int,2,Tuple>)))
(0 * 0 + (1 * 0 + (2 * 1))) = 2
2 -> the index of "int" inside Tuple
Essentially we multiply each index with the predicate’s result, and sum the results. The predicate (1) could be written inline, but since there’s a second use for it, it’s good to abstract it out.
Our specialization has a static assertion. By using a variation of the fold expression described above, it makes sure that only one occurrence of the type “T” exists in “Tuple”. This way, when our meta-function returns zero, we can be positive it means “index zero” instead of “does not exist”; additionally we make sure that if the type exists more than once in the tuple, a static assertion is thrown much like in the original implementation.
I understand that flattening template instantiations might not appeal to some people, so let me extend an olive branch here: when done right, compile time recursion can be OK. Take for example the “index_sequence” we use in our code, which is implemented recursively:
Implementations use an amazing trick (I believe it’s attributed to Dave Abrahams but don’t quote me on that – it certainly appeared in his work a long time ago) to lower recursion depth to Log2(N). It is based on the realization that you can use the first half of an index sequence to build the second half, by adding an initial offset:
Ubiquitous library facilities are reusable. What this means, is that if someone instantiated an index sequence of twenty elements, most probably this will be shareable in your implementation.
Finally, if we end up using recursion (hope not but…), simplicity should compensate for potential hazards. Here’s how I’d solve the same problem recursively, with a single function:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Not much explanation is needed apart from the fact that I’ve opted to return the 1-based index and use 0 when the search fails, instead of a compilation error. We also avoid compilation error when more that one instances occur, by returning the index of the first match, thus short-circuiting template instantiations.
Disclaimer
If you’re in a situation where such things matter, always always measure: measure compilation time, executable size, check generated symbols, check compilation in different platforms (time and again I’ve seen VS struggle with sizes & symbol generation that gcc would simply optimize out and discard). I only wrote this post because it’s good to know your options.
This installment elaborates on the creation of a “sorted_view” utility. The “References” section contains links to the complete code; throughout the article, we provide demos and snippets to showcase and explain the implementations. The section on modernizing the code contains real world applications of the following C++17 features:
structured bindings
template argument deduction for class templates
Problem description
Apply a relative sorting on two or more data sequences, i.e take the sequences
This is a common problem in modern packaging. I’ve answered to exactly this problem description here. The “sorting by indices” techniques I used is much better explained (and extended and prepackaged) by Raymond Chen in a great series of articles you can start reading here.
What to expect
This is an example of how higher abstractions can give better performance. What we do, instead of delaying or minimizing expensive swap / copy / move operations (as in the sources linked so far), is to create a literate view for our sequences that will give us the desired sorted step through and avoid touching the sequences.
2. Design a sorted view
Any goals that are not immediately clear will be explained shortly after.
Goals
Don’t mutate the original sequences
Don’t make any copies of the original sequences
Allow custom comparators to be used for sorting
Easy “sorted walks”
Ability to use other sequences as tie breakers
Tools
The few Standard Library components we’ll use to make our life simpler:
A tuple to hold the (one or more) sequences
A vector of indices that holds the step through order
The sort and iota algorithms
3. Implementation
In a nutshell, our class will look like this
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Since spelling out the type of our class is quite cumbersome and error prone, we’ll create a helper function to automate this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
So the tuple class member is referencing any l-value references and move constructing from r-value references.
Sorting
Sorting is pretty straightforward
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The I template parameter denotes the sequence we use for sorting. A lambda that uses the custom comparison function with the referenced elements of that sequence is used in the sort algorithm.
Accessing
True to our “easy access” goal we provide an access method
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
all it does is retrieve the element of the Ith sequence at the sorted position pos.
Example
Say we had the top ten of Olympic medalists. If we encode each column as a sequence (hence we’d have the sequences ‘first_name’, ‘last_name’ etc) this is how we’d use the sorted view class
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Let’s avoid standardese and just use an example. Therein the S class explicitly forbids copy construction and allows move construction; the sorted_view class captures everything as expected.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The additional clue here is that if the two definitions of tuple_t were different, the program wouldn’t compile due to conflicts.
4. Sorting with multiple criteria
Let’s return to our original example. If we were to sort based on gold medals, we see that Mark Spitz and Carl Lewis collected an equal amount of them so we’d like to specify a tie breaker, let’s say silver medals. Nope, equal there too so let’s fall back to bronze. This process of relative sorting with fallback is what the following method does
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The Demo provides essentially the following use case
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
i.e. sort based on total medals (sequence 9), then gold (6), then silver (7) and finally bronze (8). Complete code can be found in the references in case you ‘re wondering how is the equality operator generated (we only pass one comparator) or how to actually apply the fallback comparisons (generic lambdas are great by the way).
5. What can we get out of c++17
I hate the “I have this hammer, are there any nails” approach. The things we’ll work on modernizing are actual shortcomings of the pre C++17 code version so don’t expect a cornucopia of features. That been said, I find the following language additions exceptional.
No more “make_stuff” stuff
Template argument deduction for class templates is here to eliminate most cases of make_something helper functions. Though they might not look like such, the following are class template instantiations:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Implicitly synthesized Deduction Guides (from existing constructors) take over the task of spelling out the class type (which in this case matches the desired behavior in terms of capturing). We can also specify our own deduction guides explicitly but this deserves its own post. Also note that the type of the two variables declared above is different (different instantiations of the same class template).
NOTE: A nitpicker might have noticed that since the beginning the sorted view constructor didn’t use forwarding references but mere r-value references. That was so that we’d take advantage of reference collapsing rules and have the C++17 extension work out of the box in the desired fashion. If you don’t believe me make the constructor templated in the Demo below and see if template argument deduction for class templates works (spoiler … it doesn’t).
Accessible access
The way we accessed the sorted view elements was kind of awkward, mostly because the user had to be quite familiar with the class interface. Secondly because even then, unless we went the extra mile to bake “named tuples” into sorted_view, no one would be comfortable using the indexes of the inner tuple without looking at the instantiation (I used many fields in the initial example make this obvious).
Structured bindings provide a simple way to decompose a class (destructure one might say) but even better, you can do this your own way! Since destructuring the data holder of the sorted view (the inner tuple) doesn’t do much good, here’s what we’ll provide :
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Every binding is an instance of class that holds pointers to a tuple element and the sorted indices
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Also, this type provides a sorted access through an overloaded subscript operator:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Now this makes the code way clearer with minimum effort. Here’s what it took to provide custom structured bindings for our class:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
It’s worth mentioning that ADL allows getto be written inside the utl namespace (there’s a dispute on Reddit on whether writing it inside std would be UB). Usage of the techniques mentioned in this section can be found in the following Demo
6. Extensions
There are things to consider in order to augment the functionality of the sorted view class:
Provide an interface so that sort could take advantage of C++17 parallel sorts if desired
Raymond Chen has an article on the Schwarzian transform, maybe this would be good to have
Custom view should be also possible. Why just sort, a lot of other stuff can be done the same way (my first attempt cluttered the interface so until I find a way to keep simple things simple, having a dedicated class is OK)
Provide named tuples for the C++14 implementation
Concepts: the elements sorted_view acts upon, have to be sortable, indexable etc and all these are constraints wonderfully expressed with concepts (you should see the errors I got while writing this w/o concepts).
On most of the points above, I’ll return with a dedicated post, until then thank you for reading.
Quantification expresses the extent to which a predicate is true over a set of elements. Two forms are the most common:
Universal
Existential
To define the quantifiers, let A represent an expression, and let x represent a variable. Then:
Universal Quantification: If we want to indicate that A is true for all possible values of x, we write ““. Here is called the universal quantifier, and is called the scope of the quantifier. The symbol is pronounced “for all“.
Existential quantification: If we want to indicate that A is true for at least one value of x, we write ““. This statement is pronounced “There exists an x such that A“. Here is called the existential quantifier, and A is called the scope of the existential quantifier.
We elaborate on the topic as follows: In section 2 we describe quantification in the template metaprogramming context, in section 3 we explore related standard library facilities introduced in C++17 and section 4 adds concepts to the equation. Finally, in section 5 we draw some concluding remarks.
2. Use in metaprogramming
Metaprograms often use predicate logic in creative ways. For example, type queries in generic code are used to constrain, dispatch, specialize, activate or deactivate code at compile time. Even until C++14, expressing predicate logic at compile time was cumbersome, when handling variadic arguments, involving a helper type and crafty use of boolean logic:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The C++17 Standard allows for much simpler (almost mathematical) syntax, by folding over the logical operators:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Above we define two variable templates that become true or false depending on the value of their (boolean) template arguments. Since they’re conceptually and syntactically simpler, as well as cheaper in terms of instantiations, we’ll prefer these to built subsequent tools.
Making the Quantifiers
To define our quantifiers we need to involve the predicates, essentially the process that produces the list of boolean we feed to the above variable templates. Let P be a predicate over a type and Ts a type list, then:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
These quantifiers could be used for example to check that a list of types is trivially copyable:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
A toy example can be found here . Of course the quantifiers can be used inline w/o stub code like the are_tc variable template above.
Generalized Predicates – Currying metafunctions
A limitation of the code so far is that it can only be used for univariate predicates. Say we had a predicate that needed 2 or more variables to compute, how would we handle it? Here the is_smaller type checks that the size of its operands is ascending:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
You might argue that “” i.e. is_smaller holds for every type T in typelist A, has no meaning and you’d be right (smaller than what?). Thankfully we need to introduce a restriction which is that multivariate predicates are to be bound until only one argument position is free and we can do that either in place (by loading the needed types throughout our interfaces) or by introducing a compile time bind, essentially currying metafunctions:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
With this in place here’s how to verify that a type is smaller than every type in a typelist:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The universal and existential quantifiers are defined in the C++17 Standard library as conjunction and disjunction respectively. Their main difference from what we defined so far is that they short-circuit in the expression level, i.e. not every expression needs to be well-formed if the result can be computed before their evaluation. This comes in handy in certain cases, but it implies they’ll have to be recursively implemented (I’m pretty sure the following implementation is attributed to Johnathan Wakely):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
i.e. we stop inheriting when the expression has computed. In contrast, our flattened instantiations implementation excels in compile times and instantiation depth violations. Choose wisely between flat and short circuiting depending on your use case.
As an example, recursive instantiationshere use an integer sequence of 18 elements to break a tuple, essentially due to its move constructor. The move constructor has a conditional noexcept that is implemented recursively. Therefore, for each template argument, a constant number of additional instantiations is required (the implementation e.g. of is_nothrow_move_constructible in terms of is_nothrow_constructible which is implemented in terms of __is_nt_constructible and so on, for 15 instantiation levels!). This means that each template argument for tuple requires 15 additional instantiation levels for this check. On top of that, 9 levels are always required (constant depth). Therefore, 17 arguments require an instantiation depth of 17*15+9 == 264 (default for clang 3.7 was 256).
Another example use of this mechanism would be to elaborate on quantification the other way around, i.e. one type vs many predicates (instead of 1 predicate vs many types we’be doing so far):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Concepts are predicates. And as such a simple extension of our quantifiers can encapsulate concepts as well:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
To get an idea of how this could be used check below:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
or this Demo (disclaimer: only to showcase the use of quantifiers with concepts, don’t try to find particular meaning in the code).
5. Conclusions
Metaprogramming is changing. For the better. Better techniques and more expressive syntax are emerging that will allow library writers to produce more elegant code. Users of this code will have a better experience due to more comprehensive compiler errors. The price we have to pay is understanding the formalities and theory involved with this ecosystem; the bet to be won is Stroustrup’s “make simple things simple” claim, so that modern C++ can be “expert friendly” but not “expert only”.
Whenever we use data structures that are compile time restricted in terms of extends, we allow for significant optimizations and early error detection in the expense of more cumbersome access style and code maintenance, due to the inevitable introduction of templated code. Users of such data types, algebraic (tuple, pair) or aggregate (array), breathed a sigh of relief (well… maybe not all of them) with the introduction of std::apply in C++17, that handles the boilerplate of unpacking their contents into a callable. To give an example, you should now be able to write your callable like so
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Remain blissfully unaware of the structure that packs your arguments (the back end doesn’t need to specialize for different argument sources)
Use the callable with any of the aforementioned data types without special treatment (the front end needs no boilerplate to unpack the data structures)
So, for example, you can know invoke your callable like so
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Handy as it may be, this ecosystem of data types and tools, leaves a lot to be desired. First and foremost, the slice operation i.e. the creation of an entity that captures a subset of some given data. My main motivation for this was to be able to pass slices to the apply function although while researching the topic I found an old freestanding request, which I’ve just answered here (isn’t it a bummer when you invent something only to discover other people have had similar musings?) Below we define the tuple_slice operation that fills this gap and elaborate on the code:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Not to be confused with valarray’s slice, this piece of code does 3 simple things:
Protects from invalid instantiations with static asserts
Forwards the container (tuple, array, pair) + an integer sequence to the implementation function
The implementation function gets every element indexed by the sequence and forwards it as a tuple i.e. lvalues are referenced and rvalues are move constructed
A slice of t can be obtained like so
tuple_slice<I1, I2>(t);
Where [I1, I2) is the exclusive range of the subset.
To be able to create slices that are not zero-based, all we do is create the index sequence out of the cardinality of the desired sequence and then offset the values. This works but a helper “make_integer_range” type would be nice to have:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
You can experiment with integer ranges here. Back to the main act then (using make_index_range to simplify the definition of tuple_slice is trivial so we’ll omit it), here are some example uses of tuple_slice:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
One might ask “Shouldn’t a slice operation on an array create another array?” and this brings us to a generic code paradox: While trying to handle more cases we may end up being more restrictive; The extra effort to create respective make_array and forward_as_array functions is not the problem (there you go if you don’t believe me). Here are the considerations:
We cannot create an array of references, hence we’d fall back to creating an array of reference wrappers. Not only does this create an interface mismatch with the tuple case (we need to call get() on a reference wrapper to obtain the value) but between lvalue and rvalue arrays as well: slicing the later would give us move constructed values, hence no get() method.
How would this logic extend to the pair case? Slicing a pair does not give us yet another pair (only in the dummy case where the slice is identical to the original) so the fallback of producing a tuple would be viewed as an exception. To me, the frequency of the word “exception” in the description of a design is inversely proportional to its quality.
Slices should handle uniformly the empty case and tuples do this .
If there’s a unique sliced type, pattern matching it would require minimum effort.
There’s always the option to create arrays out of the slices if we want to (would be interesting to see if the intermediate tuple can be optimized away) .
In a previous post we introduced C++17 fold expressions and described a way to extend them for arbitrary callables. Implementation details don’t matter for what we’re elaborating on here but it should be clear that (given the tools we developed) the following is possible:
(Op<F>(args) + ...)
(... + Op<F>(args))
i.e. performing a right or left fold respectively using the “F” type as the folding operator (the “+” operator is used just to generate the underlying expression templates). By “F” we mean a type that will serve as the reducing function (it generates callable instances) e.g. this:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Such tools enhance the notion of “reduce” being the ultimate production line where new algorithmic skeletons and processes can be forged sometimes to a surprising extend as we’ll see below.
2. On composition
In a nutshell composition is the pointwise application of one function to the result of another to produce a third one. Add another one to the pipeline and the mathematic notation goes something like this:
…and so on and so forth, we should be able to compose as many functions as we want provided that the result of the “inner” functions can be a valid input to the outer.
Now, look at the mathematical notation again. What does the right hand side look like? It’s just folding over the function call operator! Written in pseudo C++ (I say pseudo because C++ folds don’t support arbitrary operators out of the box) it would look like this:
args () ...
where args is a pack of callables we want to compose. Now it all boils down to synthesizing the reducer, and composing two callables is easy enough, by creating a lambda that applies the left side to the result of calling the right side with whatever arguments you pass to it:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
We’ve also added a helper compose function to hide the fold generation even though it’s good to know that it takes a right fold to do this. Having this in place you can write things like
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
I might have oversimplified the definition of the Comp structure. Taking move semantics into consideration is not only a matter of efficiency but correctness as well, since preserving value category is essential when using forwarded callables. To ammend this, the returned lambda will do a perfect capture using this helper type:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This type will be used by the (C++14 generalized) lambda capture to acquire either a reference (wrapper) or a moved callable (depending on its value category). So now Comp is written as follows
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Currying is the technique of translating the evaluation of a function that takes multiple arguments (or a tuple of arguments) into evaluating a sequence of functions, each with a single argument. In other words it could be described (nitpickers pardon me) by the production of partially applied functions something you see in C++ with certain applications of std::bind. Following the same logic as above we’ll be using the left fold pipeline with the following reducer
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The last piece of the puzzle is constexpr lambdas that would really allow for this to extend to synthesizing constexpr callables and this is on its way for C++17
Demo
A runnable example can be found here. Note that this particular example only runs for g++ and I’ll be diving into clang in a later endeavor.


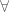

 “. Here
“. Here  is called the universal quantifier, and
is called the universal quantifier, and  is called the scope of the quantifier. The symbol
is called the scope of the quantifier. The symbol 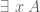 “. This statement is pronounced “There exists an x such that A“. Here
“. This statement is pronounced “There exists an x such that A“. Here  is called the existential quantifier, and A is called the scope of the existential quantifier.
is called the existential quantifier, and A is called the scope of the existential quantifier. ” i.e.
” i.e. 

{kind=link}